Retail sales became the object of controversy this year when Paul Dales of Capital Economics challenged the "conventional wisdom" that Black Friday sales are a good predictor of yearly sales. In other places (here and here) I've described how the methodology used by Mr. Dales is probably flawed (I actually don't know what methodology was used but I made some guesses based on computer simulation). Another questionable part of Mr. Dale's work is the idea that any week during the year would be a good predictor of yearly sales. Sales forecasts would typically be based on some type of macro-economic time series model that uses multiyear data, the more the better. In this post, I will use multiple state space models to predict US retail sales. The results suggest a different story about what drives yearly sales in the US retail sector.
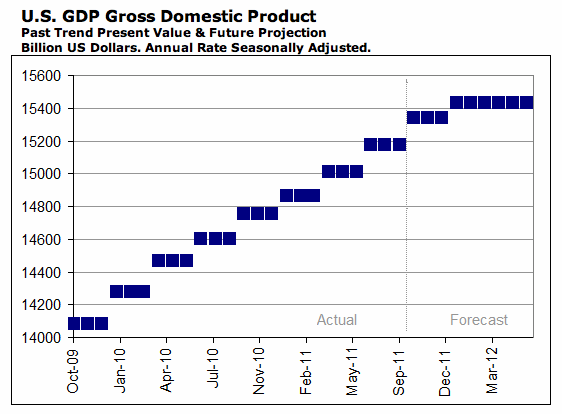
The Financial Forecast Center generates forecasts of US Retail Sales Growth Rates (here). The current forecast is displayed in the graphic above. The forecasts are generated with artificial intelligence software, not macro-economic models. As such, the FFC models do not have the biases associated with models based on a priori theoretical considerations. Their results show that retail sales growth rates have been declining since 2010 and are predicted to drop below 2% by 2013.

The FFC provides monthly, not seasonally adjusted, retail sales data (RSAFSNA) taken from the US Department of Commerce (here) in millions of dollars starting in 1992. When we plot that data for the period 2007-2012 (from the beginning of the financial crisis to the beginning of this year) we see very clearly that retail sales are elevated during the last two months of each year and that peak year-end sales pretty much follow trends for the rest of the year. The graph alone refutes the idea that Black Friday is a bunch of meaningless hype.
All this still begs the question of what is the best predictor of US retail sales. My approach is different from other forecasts that rely on models. Rather than advancing one model based on some argument, I test multiple models and choose the best one based on the AIC criterion: the best model is the one that predicts the historical data best with the fewest parameters. In this case, I tested the following models: (1) a random walk, R(t) = R(t-1) + E where R is Retail Sales and E is error, (2) a business-as-usual model, R(t) = a R(t-1) + E, (3) a state space model of the US economy, R(t) = a R(t-1) + S(US) + E where S(US) is the state of the US economy and (4) a state space model of the world economy, R(t) = a R(t-1) + S(W) + E where S(W) is the state of the World economy. The states of the US and World economy are generated by the USL20 and WL20 models, respectively.
The rationale for these models is pretty straight forward: (1) given the high variability of the data, next year's sales may well be dominated by random error (the random walk), (2) if we smooth out some of the seasonal variability, average sales might just be a little bigger this year than last year (business-as-usual), (3) more realistically, US retail sales might depend on the entire state of the US economy and (4) given the globalization of world trade in retail services, the state of the world economy may be a better predictor of US sales.

We've come a long way from the idea that Black Friday Retail Sales might be considered a reasonable predictor for yearly retail sales and learned that the US Retail Sector is part of the World economy. We've also learned that end-of-year sales are improbably (outside the 98% prediction interval) important to the sector. And, we've learned that setting up a single model to test a false problem is not a particularly useful way to conduct research.
TECHNICAL NOTE: The RSAFSNA.model is available here. Instructions for using forecasting models are available here. Once you have the R program installed and the dse, matlab, and scatterplot3d packages installed, you can run the following commands from the R console to display how well the best RSAFSNA.model fits the data.
> W <- "Absolute path for location of ws procedures"
> setwd(W)
> source("LibraryLoad.R")
> load(file="WL20v3_model")
> load(file="ws_procedures")
>
> W <- "Absolute path for RSAFSNA model"
> setwd(W)
> load(file="US_RSAFSNA_model")
> m <- getModel(RSAFSNA.model,type="world index")
> tfplot(m)
You will notice that the model does not track the month-to-month variability in RSAFSNA. If we wanted to better predict things like end-of-year sales bumps, we could use seasonal dummy variables coded for the months of interest, for example November and December.
If you are interested in how the other models did, enter
> tfplot(m1 <- getModel(RSAFSNA.model,type="rw"))
> tfplot(m2 <- getModel(RSAFSNA.model,type="us index"))
> tfplot(m3 <- getModel(RSAFSNA.model,type="bau"))
The plots actually seem to do a little better job of tracking the month-to-month variability. However, the AIC still suggests that the world model is best, but not by a huge amount.
> z <- bestTSestModel(list(m,m1,m2,m3))
Criterion value for all models based on data starting in period: 10
5301.765 5354.228 5318.493 5377.438
If you want to see the entire forecast with 98% bootstrap confidence intervals, enter
> b <- getModel(RSAFSNA.model,type="boot forecast")
> tfplot(b,m)